Exécution du modèle distillé DeepSeek R1 sur les ordinateurs InHand AI Edge
DeepSeek R1, un modèle d'IA open-source, redéfinit l'efficacité et la performance dans la communauté de l'IA. Sa technologie de pointe en matière de distillation des connaissances transforme les modèles complexes en centrales légères, offrant des capacités d'inférence de premier plan. Cette combinaison d'accessibilité à des sources ouvertes et de conception légère abaisse les obstacles au déploiement de l'IA et ouvre de nouvelles possibilités pour l'informatique de pointe.

L'équipe de technologie de l'IA d'InHand Networks vient de déployer avec succès le modèle distillé DeepSeek R1 sur le site Web de l'entreprise. Ordinateurs de pointe pour l'IA de la série EC5000. Cette réalisation valide le puissant potentiel des dispositifs légers de périphérie dans les tâches d'inférence de l'IA. Par rapport aux déploiements traditionnels basés sur l'informatique en nuage, l'informatique d'IA en périphérie élimine le besoin de serveurs à haute performance, permettant l'inférence en temps réel dans des environnements à faible consommation d'énergie. Cela rend les solutions d'IA plus flexible, sûr et efficace pour des applications telles que l'inspection de la qualité industrielle, les transports intelligents et la télémédecine.
Exécution du modèle distillé DeepSeek R1 sur les ordinateurs EC5000 AI Edge
En quelques étapes seulement, vous pouvez déployer le modèle distillé DeepSeek R1 sur les ordinateurs de bord de la série EC5000 :
Étape 1 : Installer le Jetson Containers Toolkit de Nvidia
(Cette boîte à outils permet de gérer et de déployer efficacement des applications d'IA conteneurisées).
Exécutez les commandes suivantes pour télécharger et installer la boîte à outils Jetson Containers :
Étape 2 : Installer le kit d'outils Nvidia JetPack
(JetPack fournit des pilotes et des bibliothèques essentiels pour exécuter des charges de travail d'IA sur des appareils alimentés par Jetson).
Pour installer la boîte à outils JetPack, exécutez :
Attendre environ une minute avant de passer aux étapes suivantes.
Étape 3 : Télécharger et exécuter le conteneur Ollama
docker run -itd --runtime nvidia --name ollama ollama/ollama
Étape 4 : Télécharger et exécuter le modèle distillé DeepSeek R1 avec Ollama
Référence : Bibliothèque DeepSeek R1
Sélectionnez le modèle distillé DeepSeek R1 approprié à partir de Bibliothèque d'Ollama et l'installer automatiquement via la ligne de commande. Par exemple, pour exécuter le programme DeepSeek-R1-Distill-Qwen-1.5B modéliser, exécuter :
Vous pouvez remplacer deepseek-r1:1.5b par n'importe quel autre nom de modèle disponible à partir de Page de recherche d'Ollama.

Le tableau ci-dessous présente les modèles distillés DeepSeek R1 pris en charge par les ordinateurs de bord EC5000.

Interagir avec le modèle

Une fois le modèle en cours d'exécution, vous pouvez interagir avec lui directement via la ligne de commande, ce qui permet d'effectuer des requêtes en temps réel et d'obtenir des réponses adaptées à vos applications d'IA spécifiques.
Note : Remplacez "deepseek-r1:1.5b" par le nom du modèle que vous souhaitez utiliser, en fonction de vos besoins spécifiques.
Surveillance de l'utilisation du matériel EC5000
Pour vérifier la Utilisation du CPU, du GPU et de la mémoire de votre ordinateur EC5000 edge en temps réel, utilisez la fonction jtop commande :
L'état actuel du matériel de l'appareil s'affiche.
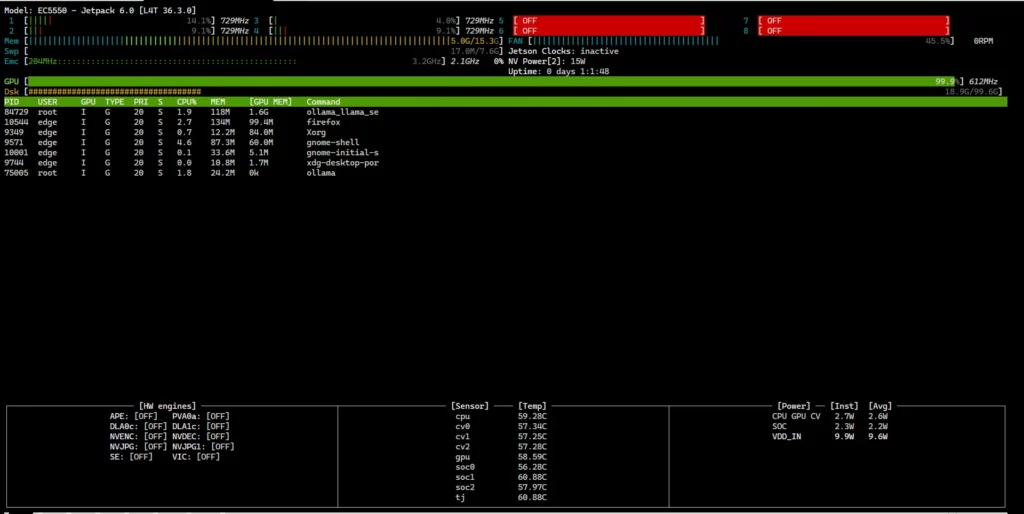
Important : La commande jtop doit être exécutée avec privilèges de la racine.
Notes complémentaires
- Outre le modèle distillé DeepSeek R1, les ordinateurs de bord de la série EC5000 prennent également en charge d'autres grands modèles de langage (LLM) libres, tels que LLaMA 3.
- Exécution de LLM sur des ordinateurs de bord EC5000 par l'intermédiaire de Ollama n'est pas la seule méthode disponible - d'autres options de déploiement peuvent être explorées en fonction de vos besoins spécifiques.
Le déploiement du modèle distillé DeepSeek R1 sur la série EC5000 démontre l'intégration transparente de l'IA de pointe avec le matériel informatique de pointe, ouvrant la voie à une nouvelle ère d'IA de pointe légère et performante.
Alors que la technologie de distillation continue d'évoluer, les entreprises peuvent tirer parti de ces avancées pour créer des services d'IA privés, en réduisant les coûts informatiques tout en garantissant la sécurité des données. Ces progrès ouvrent des perspectives de transformation dans tous les secteurs - de la fabrication et du transport intelligents aux diagnostics de santé et aux véhicules autonomes - en permettant le traitement local des données, la réduction de la latence, l'amélioration de la confidentialité des données et la prise de décision en temps réel.
InHand Networks se consacre à l'avancement de l'écosystème de l'intelligence périphérique, en permettant aux entreprises du monde entier d'adopter l'avenir de l'informatique périphérique intelligente.
Produits apparentés :
